
True Life: I’m A Digital Hoarder
Yesterday, I dedicated a few hours to organizing my digital life..(read: definitely not procrastinating).
Over the last week, I’d been noticing more than ever: duplicated files, confusing naming conventions, and junk files spread around generally.
In the walled garden of devices & services Apple™️ has built, I haven’t worried much about storage space, thank you iCloud™️. Naturally, over the years, the junk kept piling up.
Since I purchased my first Macbook™️ in 2013 (?), I’ve since: graduated college, changed jobs six times, worked on side projects, moved cross country, and all along the way generated junk. Vacation pictures (that already live in Photos™️), documents (duplicated across computers locally and in the iCloud™️), screenshots (because proof), and on and on.
Last night, I finally decided to do something about the unorganized slop that I’d been dealing with. That’s when I came across an interesting file: an early mockup/proof-of-concept (POC) of an application I was preparing to pitch back in 2016.
Time Is A Circle
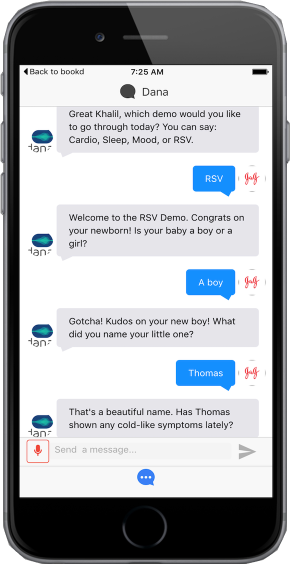
That year, I was in my first post-college job at a healthcare company, working on what we called digital health products.
A platform called DialogueFlow, which allowed developers to build out semi-structured AI conversations had recently been released. If you read The Last Arms Race Pt.1, you’re probably aware that interest in AI was picking up again right around this time.
For a variety of reasons I believed the technology presented an opportunity for the business, so I went about developing the POC and pitching potential use-cases to my team.
If you know me, you know I’ve never been short on ideas, and fortunately, my job at the time was—in part—to be the idea guy.
But, that’s not the idea I want to talk about today.
If You Build(L) It
There’s been an idea gaining in popularity within the tech community over the last few years. The premise? Build in public.
The theory is, if you’re open about what you’re building, and bring a community along that journey, you end up: getting crucial early feedback, to figure out if there is a market, and identifying early customers/users.
What a dumb thing to do, someone will definitely steal your idea!
But no, ideas really are a dime a dozen. What matters most is execution.
So, that’s what I’ll be doing here on Sundays. Building in public, and bringing you all (if there is a you all..at all?), along for the ride, as I take the electrical signals zooming around in my brain and manifest them into a product.
What’s The Point, Khalil?
Am I this long-winded in conversation or is this an entirely written-communication phenom? If it’s the former, apologies friends.
Cutting to the chase:
Machine learning models, especially large language models (ChatGPT, Claude, DeepSeek, etc.) are being integrated across nearly EVERY single product and service. Most people have now interacted with AI/ML—via their jobs, or various other ways (like googling).
A vision for AI has always been that we could have personalized intelligent assistants in our pockets, ready to respond to any and all requests. The industry is still working towards that goal, but at least as far as I can tell, there is a particular gap in development, rather, an opportunity—that is begging to be addressed.
Each new “conversation” with one of these models is sort of like being at a speed dating event. The model doesn’t know you, what your preferences are, or, critically—have access to much of the context it may need to respond most effectively. For any complex task or question, users often have to share repetitive information with models.
That is the first problem I want to solve with what I’m calling AgentBuddy (name is a WIP alright, the right side of my brain is typically snoozing).
The core features/pitch of AgentBuddy are:
- Users build out libraries of their data, either directly in the platform, or by linking other services (Evernote, Notion, Google Drive, etc.)
- Via customizable built in system prompts (which are pre-instructions given to a model), the AI interactions users have can always feel personal and useful without unnecessary repetitiveness.
- Simple commands made available in chat with the model allow users to reference data they’ve added to their library, further enhancing its capabilities.
- Cheaper via model democratization.
- For most end-users today, the interface they are familiar with when it comes to AI is ChatGPT. In fact, I would be willing to bet that for some portion of the population, ChatGPT has become synonymous with AI in the mindshare.
- For intermediate users, and beginners who grow in comfort, AgentBuddy will allow model selection beyond a single provider (i.e. OpenAI), to any of the providers hosted on OpenRouter (Claude, DeepSeek, Mistral, etc.). This allows those users to get more out of the platform at a cheaper cost than many others.
The second phase includes a set of business applicable features, however I’ll be keeping those private for now as they just might be worth a quarter.
Progress So Far
The build out of this platform started ~2weeks ago and this is my current progress towards MVP (minimum viable product).
- Backend – 75%
- (What you might know as the “servers”)
- Complete:
- Data models
- Database integration
- OpenAI and OpenRouter integration
- API routes
- Authentication and security
- Mobile App – 30%
- (Substantially reducing scope, because release is what matters most)
- Complete:
- App structure and routing
- Design system and theme
- Backend integration (not reflected in UI yet)
- State management + hooks
- Apple and Google authentication
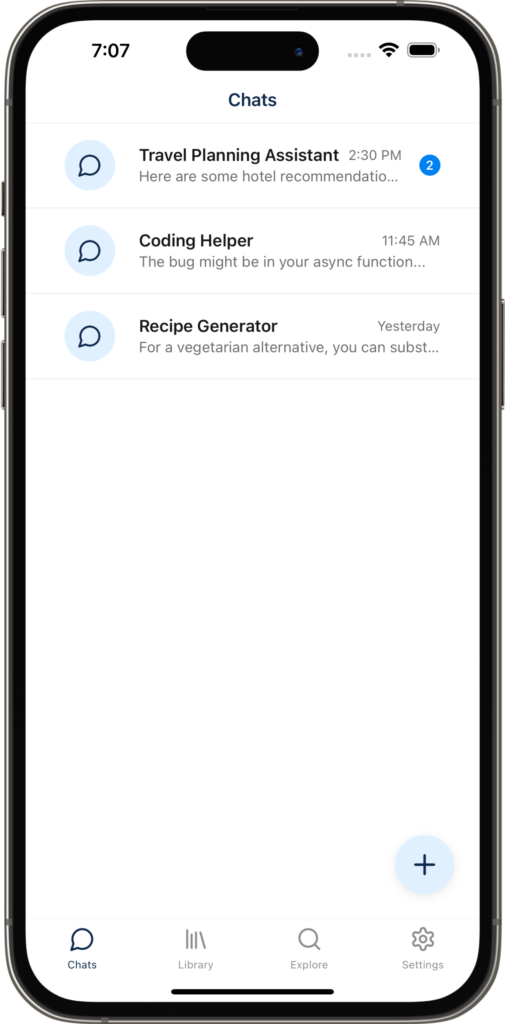
In a future post, I’ll go into more detail about not just this app, but how I approach analyzing a potential product, doing early market and technical research, and going from idea to proof-of-concept.
Thanks for reading!

